
ライブラリのimport
競馬データをスクレイピングするために必要な下記のライブラリをimportします。
・pandas
・re
・BeautifulSoup
・requests
import pandas as pd
import re
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm馬情報のスクレイピング
馬情報はnetkeibaさんの下記のページから馬情報(基礎情報・血統情報)を取得します。
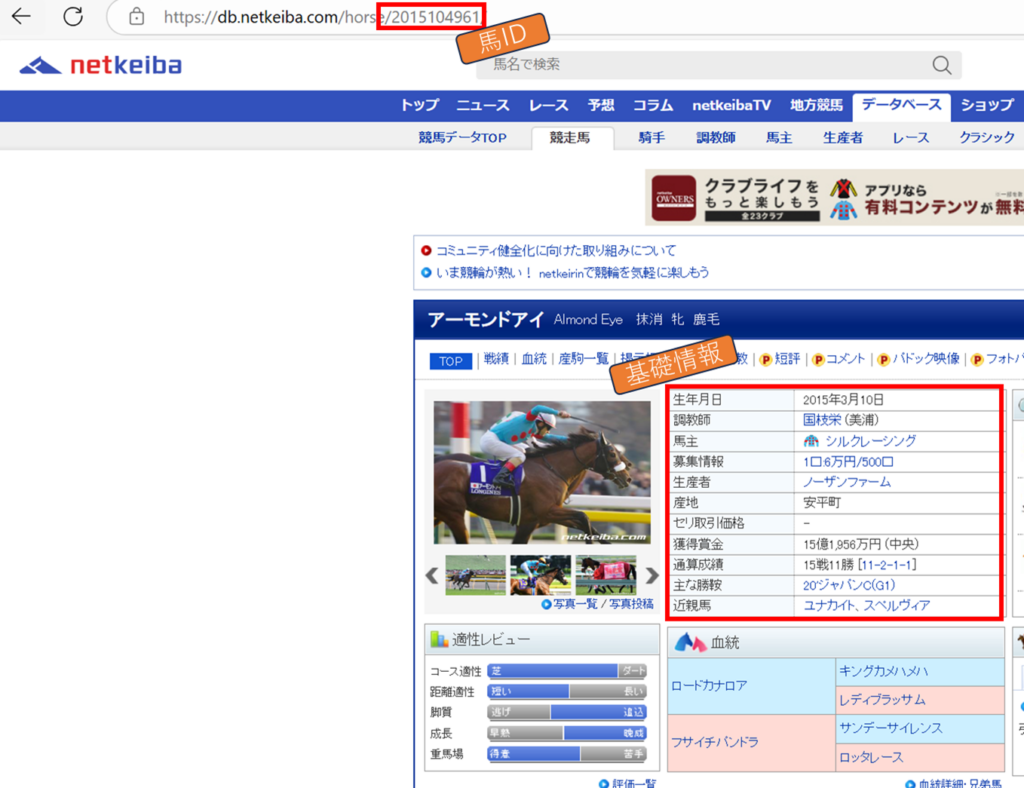
基礎情報
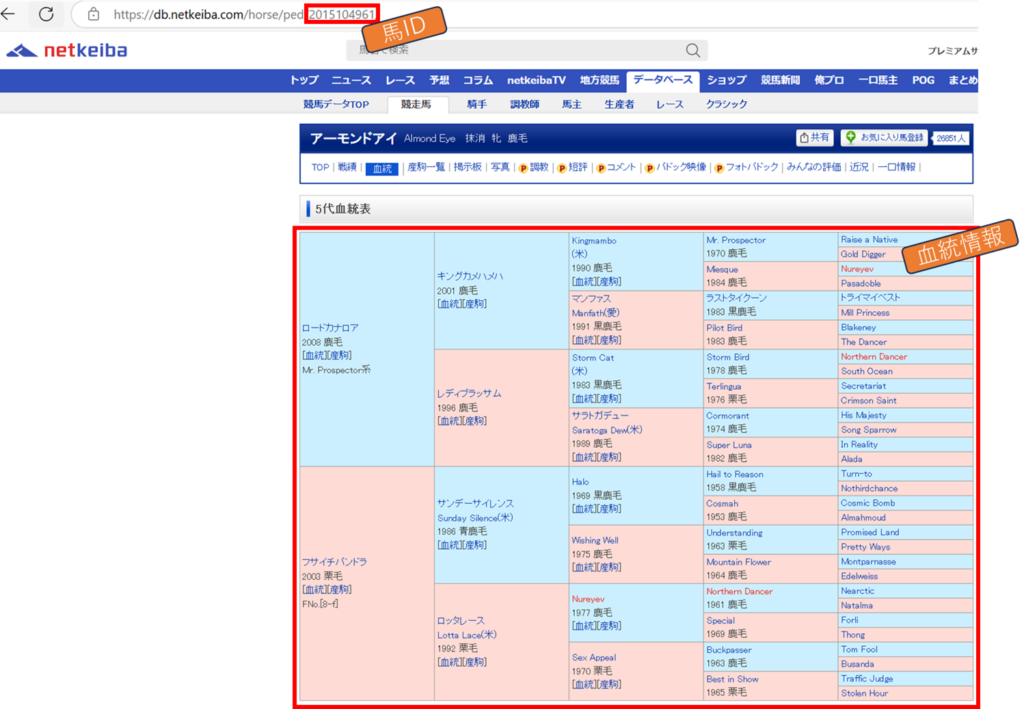
血統情報
netkeibaでは競走馬に独自の馬IDを付与し、馬IDにて競走馬のURLを設定しております。
馬情報の収集にあたっては馬IDのリストを作成する必要があるので、馬IDリストを作成します。
レース結果の収集で各レース結果を収集する際に馬IDも取得しておりますので、こちらのデータをもとに馬IDリストを作成します。
馬IDリストの作成
レース結果の収集で保存した”競馬データ.csv”を読み込み、こちらのデータに存在する競争馬の馬IDのリストを作成します。コードは以下になります。
(〇〇には”競馬データ.csv”が保存されているパスを記入ください。)
uma_id_list=pd.read_csv("〇〇")["馬ID"].unique().tolist()基礎情報、血統情報の取得
馬の基礎情報や血統情報はHPで表形式で記載されているため、pd.read_html()で取得できますが、項目名が行方向に記載されており、データ加工するのが難しいため、BeautifuiSoupで情報を取得します。
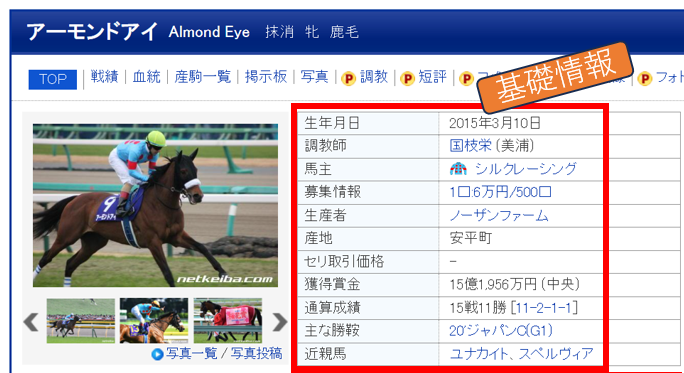
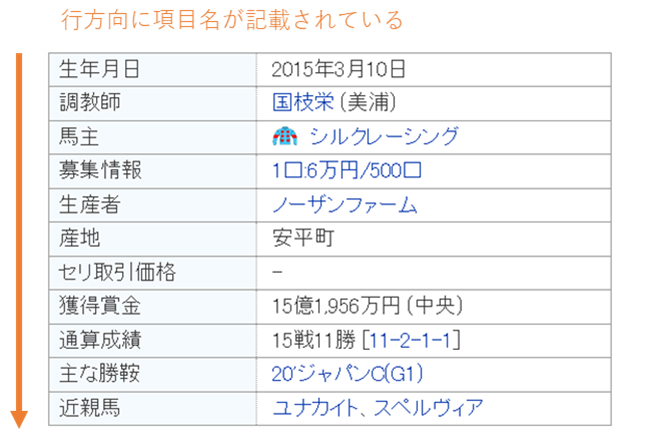
✅項目名が行方向に記載されており、pd.read_html()で表データを取得してもデータを扱いにくい
✅BeautifulSoupを用いて情報を取得する。
まずは、requestとBeautifulSoupを用いて、競争馬のページのWEB情報(HTML)を取得します。
#requests関数でURL先のページからWEB情報を取得する。
res=requests.get(f"https://db.netkeiba.com/horse/2015104961/")
#BeautifulSoupで取得したWEB情報を解析する
soup=BeautifulSoup(res.content,"lxml")✅基礎情報のページはhttps://db.netkeiba.com/horse/馬ID/
✅血統情報のページはhttps://db.netkeiba.com/horse/ped/馬ID/
WEB上のレース情報を変数soupに格納したので、ここから基礎情報・血統情報を抜き出します。
CSSセレクタというWEN情報(HTML)の住所を示したものを利用して抽出します。
(CSSセレクタについては、他のHPの解説を利用ください)
基礎情報・血統情報のCSSセレクタは以下になります。
~基礎情報~
生年月日:”th:-soup-contains(‘生年月日’) + td”
調教師:”th:-soup-contains(‘調教師’) + td”
馬主:”th:-soup-contains(‘馬主’) + td”
生産者:”th:-soup-contains(‘生産者’) + td”
産地:”th:-soup-contains(‘産地’) + td”
基礎情報は上記のセレクタで取得可能です。
~血統情報~
血統父:”tr:nth-child(17) > td.b_fml > a:nth-child(1)”
血統母:”tr:nth-child(1) > td:nth-child(2) > a:nth-child(1)
血統父父:”tr:nth-child(9) > td.b_fml > a:nth-child(1)”
血統父母:”tr:nth-child(17) > td:nth-child(2) > a:nth-child(1)”
血統母父:”tr:nth-child(25) > td.b_fml > a:nth-child(1)”
血統母母:”tr:nth-child(1) > td:nth-child(3) > a:nth-child(1)”
血統情報については、上記CSSセレクタで情報を取得すると、血統情報を表す馬IDの他に余分な部分まで取得してしまいますので、必要な部分のみ取得します。
(父の血統情報の取得例)
soup.select_one(“tr:nth-child(17) > td.b_fml > a:nth-child(1)”で父の血統情報を取得すると、
以下のように余分な部分まで取得してしまう。
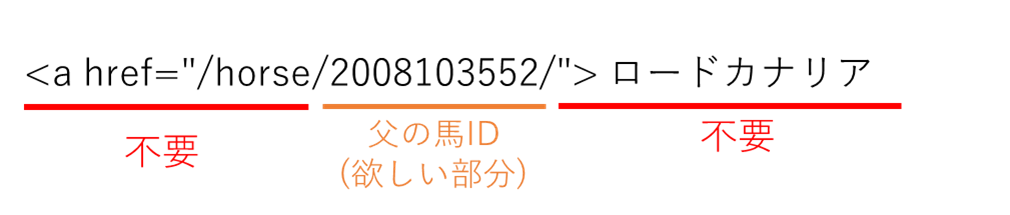
このため、正規表現を使って馬IDの部分(数字3文字と任意の7文字で構成される箇所)のみを取得します
re.findall(r”\d{3}.{7}”,str(soup.select_one(“tr:nth-child(17) > td.b_fml > a:nth-child(1)”)))[0]
上記コードで父の馬IDである2008102552を取得できます。
Pythonコードのまとめ
馬IDリストの作成から馬情報(基礎情報・血統情報)の取得をまとめたコードは以下になります。
##ライブラリインポート
import pandas as pd
from tqdm import tqdm #進行状況を表示させるライブラリをインストール
import re
from bs4 import BeautifulSoup
import requests
#馬IDのリストを作成する。
uma_id_list=pd.read_csv(〇〇)["馬ID"].unique().tolist()
#馬情報(基礎情報・血統情報)の取得
#各馬の情報を入れる空のリストを作成
empty_list=[]
for i in tqdm(uma_id_list):
#ある馬の情報を入れるリストを作成
uma_list=[]
try:
##血統情報が記載されたhtmlを取得
res=requests.get(f"https://db.netkeiba.com/horse/ped/{i}/")
soup=BeautifulSoup(res.content,"lxml")
#父
uma_list.append(re.findall(r"\d{3}.{7}",str(soup.select_one("tr:nth-child(17) > td.b_fml > a:nth-child(1)")))[0])
#母
uma_list.append(re.findall(r"\d{3}.{7}",str(soup.select_one("tr:nth-child(1) > td:nth-child(2) > a:nth-child(1)")))[0])
#父父
uma_list.append(re.findall(r"\d{3}.{7}",str(soup.select_one("tr:nth-child(9) > td.b_fml > a:nth-child(1)")))[0])
#父母
uma_list.append(re.findall(r"\d{3}.{7}",str(soup.select_one("tr:nth-child(17) > td:nth-child(2) > a:nth-child(1)")))[0])
#母父
uma_list.append(re.findall(r"\d{3}.{7}",str(soup.select_one("tr:nth-child(25) > td.b_fml > a:nth-child(1)")))[0])
#母母
uma_list.append(re.findall(r"\d{3}.{7}",str(soup.select_one("tr:nth-child(1) > td:nth-child(3) > a:nth-child(1)")))[0])
except:
pass
try:
#生年月日、調教師、馬主、生産者、産地が記載されたhtmlを取得
res=requests.get(f"https://db.netkeiba.com/horse/{i}/")
soup=BeautifulSoup(res.content,"lxml")
#生年月日、調教師、馬主、生産者、産地を取得する
birthday= soup.select_one("th:-soup-contains('生年月日') + td").text
tyoukyou= soup.select_one("th:-soup-contains('調教師') + td").text
banushi= soup.select_one("th:-soup-contains('馬主') + td").text
seisansya= soup.select_one("th:-soup-contains('生産者') + td").text
sanchi= soup.select_one("th:-soup-contains('産地') + td").text
#ある馬情報をいれるリストに生年月日、調教師、馬主、生産者の情報を追加
uma_list.extend([f"{i}",birthday,tyoukyou,banushi,seisansya,sanchi])
#ある馬の情報を示したデータフレームを作成
uma_b=pd.DataFrame([uma_list],columns=["F", "M", "FF", "FM", "MF", "MM","馬ID","生年月日","調教師","馬主","生産者","産地"])
#データフレームのカラムの並べ替え
uma_b=uma_b[["馬ID","生年月日","調教師","馬主","生産者","産地","F", "M", "FF", "FM", "MF", "MM"]]
#ある馬の情報を示したデータフレームを空のリストに入れる
empty_list.append(uma_b)
except:
pass
#各馬の情報を一つデータフレームに統合
uma_info=pd.concat(empty_list,axis=0) #血統情報・生年月日、調教師、生産者、産地の情報
#csvで保存する。
uma_info.to_csv("馬情報.csv")これにより下記のような馬情報をまとめたデータが作成できます。

投稿者プロフィール

-
独学でpythonを学び競馬予測しています。これまでの競馬成績は以下の通り。回収率150%を目指します。
2021年回収率:119%
2022年回収率:104%
2023年回収率:121%
2024年回収率:88%
最新の投稿
- 競馬データの前処理・特徴量作成2024年12月30日騎手勝率
- 競馬よもやも話2024年11月28日競馬予想モデルと狙うべき馬券
- 競馬データの前処理・特徴量作成2024年11月27日馬年齢(日齢)と日齢を使った派生特徴量
- 競馬よもやも話2024年11月24日予想モデルの改良タイミング
