
LightGBMとは
light GBM(Light Gradient Boosting Machine)とは、機械学習における分析アルゴリズムであり、教師あり学習と呼ばれるデータ分析方法の一つです。
lightgGBMは決定木と呼ばれる機械学習の手法を用いて、あるデータから結果を予測するモデルを作成することができます。lightGBMはPythonのライブラリとして無償で公開されており、誰でも無料で使用することができます。
決定木とは
決定木分析とは、データから以下のような決定木と呼ばれる樹形図を作成し、予測や検証をする分析です。
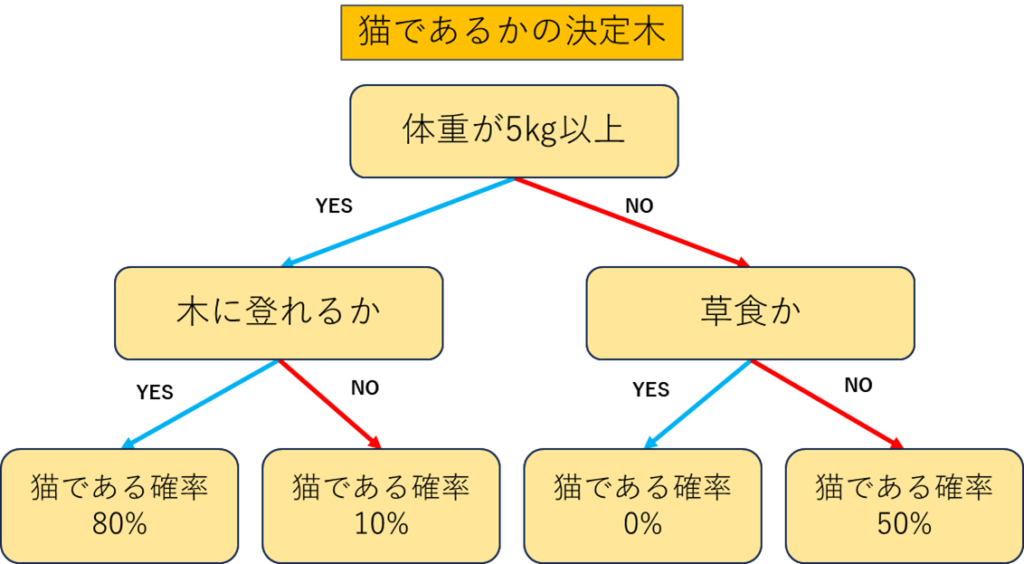
決定木のメリットとして、数値データ(体重)も質的データ(木に登れるか)も扱えることができることです。一方で決定木は1本だけでは精度が悪いというデメリットがあります。
LightGBMでは、決定木に勾配ブースティングという方法で手法を適用し、高精度の予想モデルの作成を実現させています。
勾配ブースティングを用いた決定木の分析手法
決定木は1本では精度が低いため、決定木を何本も作って予想モデルを作成します。この時、新しく作る決定木は前のモデル(決定木)が見つけきれなかった部分をちょっとずつ修正していくように働きます。具体的な流れを説明すると:
- 最初の決定木を作る
最初の決定木がデータに対する最初の予測を行います。もちろんこの予測は完全ではなく、誤差が生じます。 - 誤差(残差)を次の決定木で修正
最初の決定木で出た誤差に注目して、それを修正するための2つ目の決定木を作ります。このとき、前の決定木でうまくいかなかったところを重点的に学習します。 - これを繰り返す
新しい決定木がその前の決定木の「失敗」をどんどん修正していくというステップを繰り返して、最終的に全ての決定木が協力し合って良い予測ができるようにします。
LightGBMは、こうした「ちょっとずつ修正していく」という勾配ブースティングのアイデアを使っていますが、高精度な決定木モデルを作成します。
lightGBMの予測方法
PythonでlightGBMを使って予想モデルを作成する手順を説明します。
テーマは学生が試験に合格するかです。
①データの準備と分割
まずは予想モデル作成用のデータを自作します。
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データフレームの作成
np.random.seed(42) # 再現性のためのシード設定
# 仮の特徴量データ
data = pd.DataFrame({
'勉強時間': np.random.uniform(1, 10, size=100), # 1~10時間の勉強時間
'出席率': np.random.uniform(50, 100, size=100), # 50~100%の出席率
'過去の成績': np.random.randint(60, 100, size=100), # 60~100の過去の成績
'課外活動': np.random.randint(0, 5, size=100) # 0~4の課外活動の参加数
})
# 合格判定の条件を緩和(重みと合格基準の調整)
data['合格'] = (data['勉強時間'] * 0.2 + data['出席率'] * 0.5 + data['過去の成績'] * 0.2 +
data['課外活動'] * 0.1 > 60).astype(int) # 合格基準を60に設定
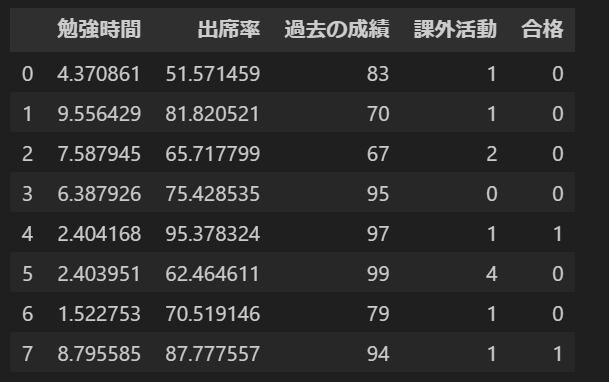
上記を出力すると、下記のようなデータセットが出来上がります。
目標変数:合格
説明変数:勉強時間、出席率、過去の成績、課外活動
となっています。合格のカラムにおいて、1は合格、0は不合格を表します。
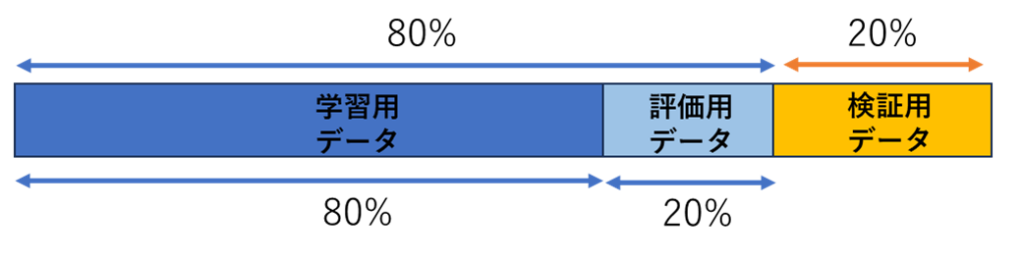
データの作成が完了したので、、全データを「8:2」に分け、20%を検証用データとして確保します。残り80%をさらに「8:2」に分割して学習用データと評価用データにします。
#目的変数Xと説明変数yを作成
X = data.drop('合格', axis=1)
y = data['合格']
from sklearn.model_selection import train_test_split
# Step 1: 全データを8:2に分割し、検証用データを確保
X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 2: 残りの80%のデータをさらに8:2に分割し、学習用と評価用データに分ける
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full, test_size=0.2, random_state=42)
この手順で、以下の3つのデータセットが作成されます:
- 学習用データ (約64%):モデルの学習に使用
- 評価用データ (約16%):early stoppingなど学習中のモデルの性能評価に使用
- 検証用データ (20%):最終的なモデルの性能を確認するために使用
②LightGBMデータセットの作成
ightGBM用のデータ形式であるDatasetに変換します。学習用データと評価用データをDatasetとして用意し、検証用データはそのまま保持します。
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
③パラメータの設定
LightGBMモデルのパラメータを設定します。学習率や木の深さなどの基本設定を行います。
params = {
'objective': "binary", #予想の目的 回帰ならregression,2値分類ならbinary
'metric': 'binary_logloss', # 評価指標
'boosting_type': 'gbdt', # ブースティングの種類
'num_leaves': 31, # 木の複雑さを制御
'learning_rate': 0.05, # 学習率
'verbose': -1 # 出力を抑える
}
④モデルの学習
early_stopping_roundsを指定することで、評価用データでの精度が一定回数改善されない場合に学習を自動で止めます。
model = lgb.train(params,
train_data,
valid_sets=[train_data, valid_data],
num_boost_round=1000,
callbacks=[lgb.early_stopping(stopping_rounds=20),lgb.log_evaluation(period=5)])
最終的なモデルの評価(テスト用データを使用)
学習が終わったら、検証用データで最終的なモデルの性能を確認します。学習や評価に一切使っていないデータでの精度を測定することで、実際のパフォーマンスを正確に評価できます。
y_test_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_test_pred_binary = (y_test_pred >= 0.5).astype(int) # 0.5を閾値にして二値化
# 正答率の計算
accuracy = accuracy_score(y_test, y_test_pred_binary)
print(f'テストデータにおける正答率: {accuracy}')この分割方法で、最初の80%でモデルを作りながら、その性能を20%の検証用データで評価することができます。
投稿者プロフィール

-
独学でpythonを学び競馬予測しています。これまでの競馬成績は以下の通り。回収率150%を目指します。
2021年回収率:119%
2022年回収率:104%
2023年回収率:121%
2024年回収率:88%
最新の投稿
- 競馬データの前処理・特徴量作成2024年12月30日騎手勝率
- 競馬よもやも話2024年11月28日競馬予想モデルと狙うべき馬券
- 競馬データの前処理・特徴量作成2024年11月27日馬年齢(日齢)と日齢を使った派生特徴量
- 競馬よもやも話2024年11月24日予想モデルの改良タイミング
