
LightgGBMを用いた競馬の着順予測(2値分類)
LightGBMを用いて競馬の着順予測する方法を紹介します。今回は2値分類を用いて、着順予測をする方法を説明します。2値分類は、最も基本的な分類の一つで、「YES/NO」や「1着になるかどうか」といった形でデータを2つのクラスに分類し、予測する方法です。
目的変数の設定
2値分類を行うにあたって目的変数を設定します。競馬予測の場合、2値分類の目的変数としては、
“1着になるかどうか”や”3着以内(馬券内)になるかどうか”で設定するのが一般的です。ここでは、目的変数を”3着以内になるかどうか”で設定し予測する方法を説明します。
”なぜ1着になるかどうか”を目的変数にしないのか
”1着になるかどうか”を目的変数に設定し、精度良い予想モデルを設定するのは以下の理由で難易度が高いです。
・データの偏り
「1着予測」は、各レースで1着になった馬が少ないため、データが非常に偏りやすいです。 1レースに1着馬は1頭しかいないため、1着のデータが圧倒的に少なく、これがモデルの学習に大きな影響を与えます。対して「3着以内予測」は1レースあたり3頭が該当するため、正例(=3着以内)が多く、バランスの良いデータが得られます。バランスが取れている方が、モデルは学習しやすく精度は高くになります。
・モデルの学習パターンが限られる
「1着予測」の場合、各レースで1頭しか正例がないため、モデルが学習するパターンも非常に限られてしまいます。「3着以内予測」では、3着以内に入る馬の特徴を幅広く捉えられるため、モデルの汎用性や予測精度が向上します。
・確度の高い1着予測を得られにくい
後述しますが、LightGBMで2値分類にて予想モデルを作成した際、予想結果は”1位になる”or”1位にならない”といったように2択で出力されるものではありません。予想結果は0.8だったり0.5といった形で確率として出力されます。(0.8であれば80%、0.5であれば50%の確率で1位になるといった具合で予想結果がでる)
1位になるかどうかをで予想モデルを作ると、予想モデルはよほど確信のある競争馬でないと、予想結果を0.8以上で吐き出すことはありません。例えばあるレースの出場馬に対し、予想モデルで一位になる競争馬を予測させると、すべての馬の予想結果が、0.3~0.5の間で横並びになり、結局どの馬に賭ければ良いか分からなくなります。
上記の理由で目的変数は”1着になるかどうか”ではなく”3着以内になるかどうか”で設定する方が実用的かつ効果的な予測が可能になります。
特徴量(説明変数)の設定
目的変数の設定が終わったので、目的変数(3着以内かどうか)を説明する特徴量(説明変数)を設定します。特徴量としては、レースコンディション、馬の性質(基本情報)、他の競争馬との相対情報 などを取り入れます。

特徴量において特に重要なのは他の競争馬との相対情報です。
他の競争馬との相対情報が重要な理由
他の競争馬との相対情報が重要となるのは、LightGBMが予想モデルを構築する際、データセットの各行(各競走馬)毎に学習を行うからです。
すなわち、LightGBMは競馬が16頭で行うレースという認識はなく、あくまで1行のデータに含まれる特徴量とその結果(目的変数)で学習を行います。このため、行内に対戦相手の情報を入れる必要があり、それが、他の競争馬との相対情報になります。
相対情報が特徴量として組み込まれることにより、学習過程でその馬自身の能力の他、対抗馬の能力との相対位置を考慮することができ、精度の高い予測を実現することができます。
LightGBMによる予想モデルの作成手順
LightGBMを用いた予想モデルの作成手順をPythonのコードを用いて説明します。
目的変数と説明変数の作成
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
#データを読み込む
data=pd.read_csv(") #lightGBMで予想を行うためのデータファイルのパスを記入
#3着以内かどうかの列を作る
data["3着以内"]=data["着順"].apply(lambda x:1 if x>=1 and x<=3 else 0)
#目的変数(y)を作成
y=data["3着以内"]
#説明変数(X)を作成
X=data.drop(["3着以内","着順"],axis=1) #着順も消す学習用データ、評価用データ、検証用データに分割
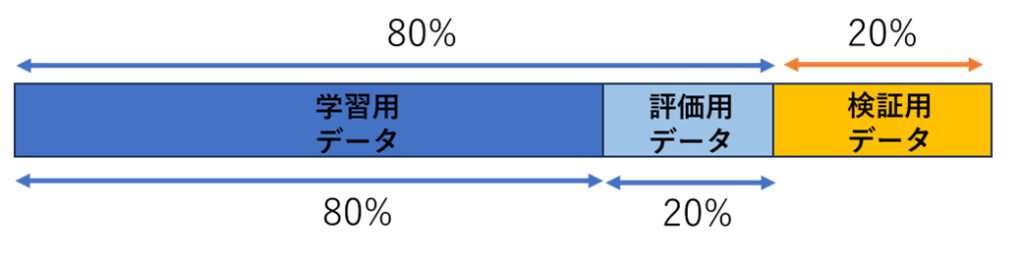
# Step 1: 全データを8:2に分割し、検証用データを確保
X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 2: 残りの80%のデータをさらに8:2に分割し、学習用と評価用データに分ける
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full, test_size=0.2, random_state=42)全データを「8:2」に分け、20%を検証用データとして確保します。残り80%をさらに「8:2」に分割して学習用データと評価用データにします。
LightGBMデータセットの作成、パラメーターの設定
#LightGBMのデータセットを作成
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
#LightGBMのパラメータの設定
params = {
'objective': "binary", # binary(2値分類)
'metric': 'binary_logloss', # 評価指標
'boosting_type': 'gbdt', # ブースティングの種類
'num_leaves': 2000, # 木の複雑さを制御
'learning_rate': 0.05, # 学習率
'verbose': -1 # 出力を抑える
}学習用データと評価用データを用いてLightGBMのデータセットを作成します。
LightGBMモデルのパラメータを設定します。学習率や木の深さなどの基本設定を行います。
予想モデルの学習
model = lgb.train(params,
train_data,
valid_sets=[train_data, valid_data],
num_boost_round=1000,
callbacks=[lgb.early_stopping(stopping_rounds=20),lgb.log_evaluation(period=5)])上記コードを実行するとPythonが学習用データで学習を行い、予想モデルが作成されます。early_stopping_roundsを指定することで、評価用データでの精度が一定回数改善されない場合に学習を自動で止めます。
予想モデルの出来栄え検証
学習が終わったら、検証用データで最終的なモデルの性能を確認します。学習や評価に一切使っていないデータでの精度を測定することで、実際のパフォーマンスを正確に評価できます。
パフォーマンスは適合率と再現率で評価します。
#混合行列を求めるライブラリをインポート
from sklearn.metrics import confusion_matrix
#作成した予想モデルと検証用データ(X_test)を用いて予想を実施
y_test_pred = model.predict(X_test, num_iteration=model.best_iteration)
#予想結果は確率であらわされるので(0.5であったり0.8だとか)、0.5を閾値にとし、
#0.5以上であれば1,それ以外は0に予想結果を変換する。
y_test_pred_binary = (y_test_pred >= 0.5).astype(int) # 0.5を閾値にして二値化
#混合行列を用いて、予想結果の出来栄えを評価
#y_test:正解、y_testpred_binary:予想モデルを使った予想結果
cm = confusion_matrix(y_test, y_test_pred_binary)
# True Positive Rate(TPR)を計算
TP = cm[1, 1]
FN = cm[1, 0]
FP=cm[0,1]
TN=cm[0,0]
再現率= TP / (TP + FN)*100
適合率=TP/(TP+FP)*100
# 正答率を表示
print("再現率:", 再現率)
print("適合率:", 適合率)
print("TP:",TP)
print("FN:",FN)
print("FP:",FP)
print("TN:",TN)上記を実行すると以下が出力されます。
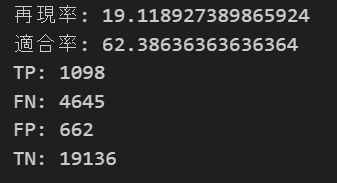
混合行列(TP,FN,FP,TN)および再現率、適合率
混合行列(TP,FN.FP,TN)は
TP:3着以内になると予想し、実際に3着以内であった数
FP:3着以内になると予想し、実際は3着以内でなかった数
FN:3着以内でないと予想し、実際は3着以内であった数
TN:3着以内でないと予想し、実際に3着以内でなかった数
で表されます。
表にすると以下になります。
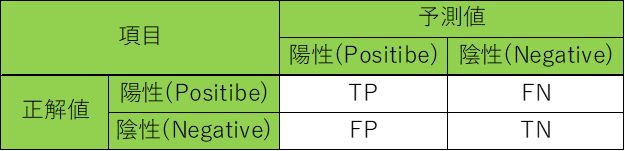
また、適合率、再現率は

上記で表されます。
競馬を予想する上で重要なのは、適合率です。適合率は簡単に言うと、勝つと予想した馬の中で、本当に勝った馬の割合です。この数値がまさに競馬予想モデルの精度を表しています。
一方で再現率は、実際に勝った馬の内、予想で勝ちと予測できた馬の割合になります。つまり、どれだけ見逃しなく、勝馬を予測できたかになります。再現率が低いと、そもそも勝馬を予想してくれなく、
例えば100レース中、80レースで、出場馬すべてが馬券外になると予想をしてしまい、勝馬を予測してくれなります。よほど硬いレースでしか勝馬を予測してくれず、機会損失につながります。
特徴量の重要度の確認方法
特徴量の重要度(Feature Importance)とは、モデルが予測する際にどの特徴量をどれだけ使って適切を数値化した指標です。LightGBMでは、各特徴量の重要度を視覚化、どの特徴量がモデルの精度に大きく影響しているのかを確認できます。
特徴量の重要度は以下のコードで確認できます。
import matplotlib.pyplot as plt
import japanize_matplotlib
lgb.plot_importance(model, height=1, figsize=(10, 30),max_num_features=500,importance_type='gain')
plt.show()
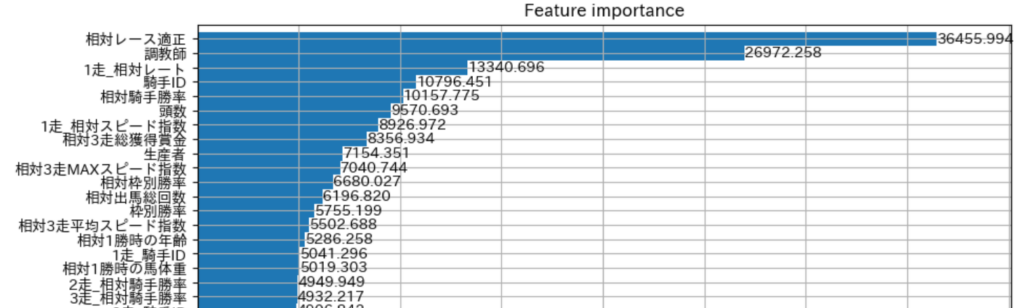
出力すると上記のように、予想モデルにおける重要度の高い特徴量が表示されます。
投稿者プロフィール

-
独学でpythonを学び競馬予測しています。これまでの競馬成績は以下の通り。回収率150%を目指します。
2021年回収率:119%
2022年回収率:104%
2023年回収率:121%
2024年回収率:88%
最新の投稿
- 競馬データの前処理・特徴量作成2024年12月30日騎手勝率
- 競馬よもやも話2024年11月28日競馬予想モデルと狙うべき馬券
- 競馬データの前処理・特徴量作成2024年11月27日馬年齢(日齢)と日齢を使った派生特徴量
- 競馬よもやも話2024年11月24日予想モデルの改良タイミング
