
クラス指数とは
クラス指数とはある拠点(競馬場・距離・フィールド)におけるクラスごとの競走馬の速さを指数化したものです。全く同一拠点であっても、G3レースやG1レースといったようにレースのクラスが違えば当然走破タイムも異なります。クラス指数はある拠点のおけるクラスごとの走破タイムの違いを指数化したものになります。
クラス指数の求め方
クラス指数は下記の式で算出します。
クラス指数=(ある拠点の基準タイムー対象のクラスの平均走破タイム)×距離指数
例えば中京1600m芝における2勝クラスのクラス指数の求め方は以下になります。
クラス指数(中京_1600_芝_2勝クラス)=(基準タイム(中京_1600_芝)-平均走破タイム(中京_1600_芝_2勝クラス))×距離指数
基準タイム:基準タイムの作成を参照
距離指数:距離指数の作成を参照
各クラスの平均走破タイムの求め方は、基準タイムの作成の方法と概ね同じです。
各クラスの平均走破タイムの算出方法
各クラスの平均走破タイムは以下の算出条件を満たすレースから算出します。
平均走破タイムの算出条件
・各レースで3着以内の馬のタイムに絞る
・馬場が良、稍のレースに絞る
平均走破タイムは、各クラスで、競馬場、距離、フィールドごとに、算出条件を満たすレースを抽出します。例えば、2勝クラスで中山競馬場、1600m、芝の条件で、算出条件を満たすレースを抽出します。100レース抽出されたとして、各レース毎に1~3着に入着した2勝クラスの馬の平均走破タイムを算出します。各レースで算出した平均走破タイムを100レースでさらに平均をとれば、その平均値が中山競馬場・1600m・芝の条件での2勝クラスの平均走破タイムになります。
Pyrhonの実装コード
Pythonでコードを書くと以下のようになります。
###クラス指数算出
##ライブラリインポポート
import pandas as pd
from tqdm import tqdm #進行状況を表示させるライブラリをインストール
import re
keiba_data=pd.read_csv(r"〇〇") #〇〇には競馬データ.csvのファイルパスを入力
#必要なデータに絞る
keiba_data=keiba_data[["競馬場","距離","フィールド","タイム","着順","馬場","系種","クラス"]]
#3着以内の馬のデータに絞る
keiba_data= keiba_data[keiba_data['着順'] <= 3].copy()
#フィールドを芝、ダートに絞る
keiba_data=keiba_data[keiba_data["フィールド"].str.contains('芝|ダ')]
#馬場を良、稍に絞る
keiba_data=keiba_data[keiba_data["馬場"].str.contains('良|稍')]
#各クラスの平均走破タイムを算出する。
#groupbyで各競馬場・フィールド・馬場・クラスごとに平均走破タイムを作る
class_indicator= keiba_data.groupby(['競馬場', '距離', 'フィールド','クラス'])['タイム'].mean().reset_index()
class_indicator.rename(columns={"タイム":'平均走破タイム'}, inplace=True)
#基準タイムをデータフレームに追加
standard_time=pd.read_csv(r"C:\Users\techm\Desktop\競馬プログラム(HP)\01_生データ\各種指数\基準タイム.csv")
class_indicator= pd.merge(class_indicator, standard_time[['競馬場', '距離', 'フィールド', '基準タイム']], on=['競馬場', '距離', 'フィールド'], how='left')
#距離指数をデータフレームに追加
standard_dis=pd.read_csv(r"C:\Users\techm\Desktop\競馬プログラム(HP)\01_生データ\各種指数\距離指数.csv")
class_indicator= pd.merge(class_indicator, standard_dis[[ '距離', 'フィールド', '距離指数']], on=['距離', 'フィールド'], how='left')
#クラス指数を計算して新しいカラムを追加するための関数
def calculate_time_difference(row):
class_time = row['平均走破タイム']
standard_time = row['基準タイム']
standard_dis= row["距離指数"]
if pd.notnull(class_time) and pd.notnull(standard_time):
return ( standard_time- class_time)*standard_dis
else:
return None
class_indicator['クラス指数'] = class_indicator.apply(calculate_time_difference, axis=1)
class_indicator.to_csv("クラス指数.csv",index=False)
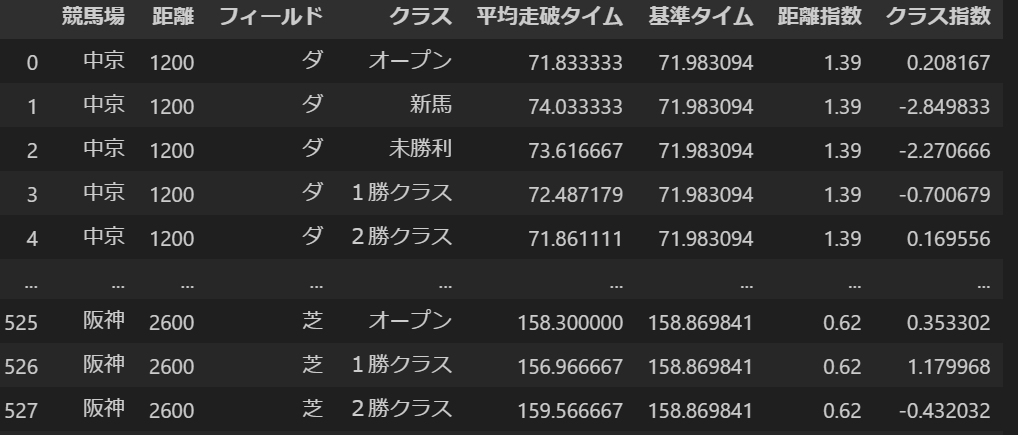
コードの出力結果は以下にようになります。
投稿者プロフィール

-
独学でpythonを学び競馬予測しています。これまでの競馬成績は以下の通り。回収率150%を目指します。
2021年回収率:119%
2022年回収率:104%
2023年回収率:121%
2024年回収率:88%
最新の投稿
- 競馬データの前処理・特徴量作成2024年12月30日騎手勝率
- 競馬よもやも話2024年11月28日競馬予想モデルと狙うべき馬券
- 競馬データの前処理・特徴量作成2024年11月27日馬年齢(日齢)と日齢を使った派生特徴量
- 競馬よもやも話2024年11月24日予想モデルの改良タイミング
