
距離指数とは
距離指数とは、異なる距離・異なるフィールド(芝・ダート)で走った競争馬の走破タイムを同じ基準で比較するための指数です。
距離指数は「1÷基準タイム×100」で求められます。
距離指数はクラスや競馬場は考慮せず、距離とフィールドのみで算出します。
1÷基準タイム×100の算出式における1は、1秒の1のことです。
1秒を基準タイムで割り100を掛けるというのは、1秒が基準タイムの何%を占めているかを求めているものになります。
例えば、1600m芝の基準タイムは94.6秒です。1秒の占める割合は1÷94.6*100=1.06%
一方で、1000m芝の基準タイムは55.4秒で、1秒の占める割合は1÷55.4*100=1.81%
すなわち、1000m芝の方が基準タイムに対して1秒の占める割合が多く、1秒の価値は大きくなります。このように1秒の価値は距離によって異なるため、異なる距離のレース結果を比較する上で、距離指数という補正値が必要となってきます。
距離指数[芝]の求め方
例えば芝1200mの距離指数の算出は以下のようになります。
距離指数(芝_1200m)=1÷(全競馬場の1200m(芝)の基準タイムの平均)×100
距離指数[ダート]の求め方
ダート1200mの場合は、距離指数の算出は以下のようになります。
距離指数(ダート_1200m)=1÷(全競馬場の1200m(ダート)の基準タイムの平均)×100
Pythonの実装コード
Pythonの実装コードは以下になります。
import pandas as pd
#基準タイム読み取り
Standard_time=pd.read_csv(〇〇) #〇〇には基準タイム.csvのファイルパスを入力
#距離指数算出に必要なカラムに絞る
Standard_time=Standard_time[["距離","フィールド","基準タイム"]]
#距離指数(芝)の算出
#フィールドを芝に絞る
shiba=Standard_time[Standard_time["フィールド"].str.contains('芝')]
#各距離の平均基準タイムを出す
Standard_shiba=shiba[["距離","基準タイム"]].groupby("距離").mean().reset_index()
#1÷平均基準タイム*100を実施
Standard_shiba["距離指数"]=1/Standard_shiba["基準タイム"]*100
#Standard_shibaに"フィールド"のカラムを追加
Standard_shiba["フィールド"]="芝"
#距離指数(ダート)の算出
#フィールドをダートに絞る
dato=Standard_time[Standard_time["フィールド"].str.contains('ダ')]
#各距離の平均基準タイムを出す
Standard_dato=dato[["距離","基準タイム"]].groupby("距離").mean().reset_index()
#1÷平均基準タイム*100を実施
Standard_dato["距離指数"]=1/Standard_dato["基準タイム"]*100
#Standard_datoに"フィールド"のカラムを追加
Standard_dato["フィールド"]="ダ"
#芝とダートで距離指数を統合する
Standard_dis=pd.concat([Standard_shiba[["フィールド","距離","距離指数"]],Standard_dato[["フィールド","距離","距離指数"]]],axis=0)
Standard_dis.to_csv("距離指数.csv",index=False)
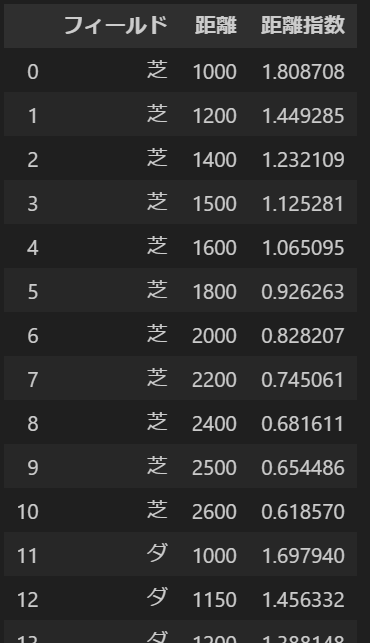
コードの出力結果は以下になります。
投稿者プロフィール

-
独学でpythonを学び競馬予測しています。これまでの競馬成績は以下の通り。回収率150%を目指します。
2021年回収率:119%
2022年回収率:104%
2023年回収率:121%
2024年回収率:88%
最新の投稿
- 競馬データの前処理・特徴量作成2024年12月30日騎手勝率
- 競馬よもやも話2024年11月28日競馬予想モデルと狙うべき馬券
- 競馬データの前処理・特徴量作成2024年11月27日馬年齢(日齢)と日齢を使った派生特徴量
- 競馬よもやも話2024年11月24日予想モデルの改良タイミング
