
競馬レース結果のスクレイピング
pythonの競馬分析の生データとなる各種競馬情報をネットからスクレイピングします。ここでは、netkeiba.comさんからデータを収集する方法を紹介します。
ライブラリのimport
競馬データをスクレイピングするために必要な下記のライブラリをimportします。
・pandas
・re
・BeautifulSoup
・requests
import pandas as pd
import re
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm①レースIDの作成
競馬のレース情報を収集するにあたり、netkeiba.comさんからデータを収集します。
netkeibaでは、すべてのレースをレースID(下図赤字)にて管理されており、
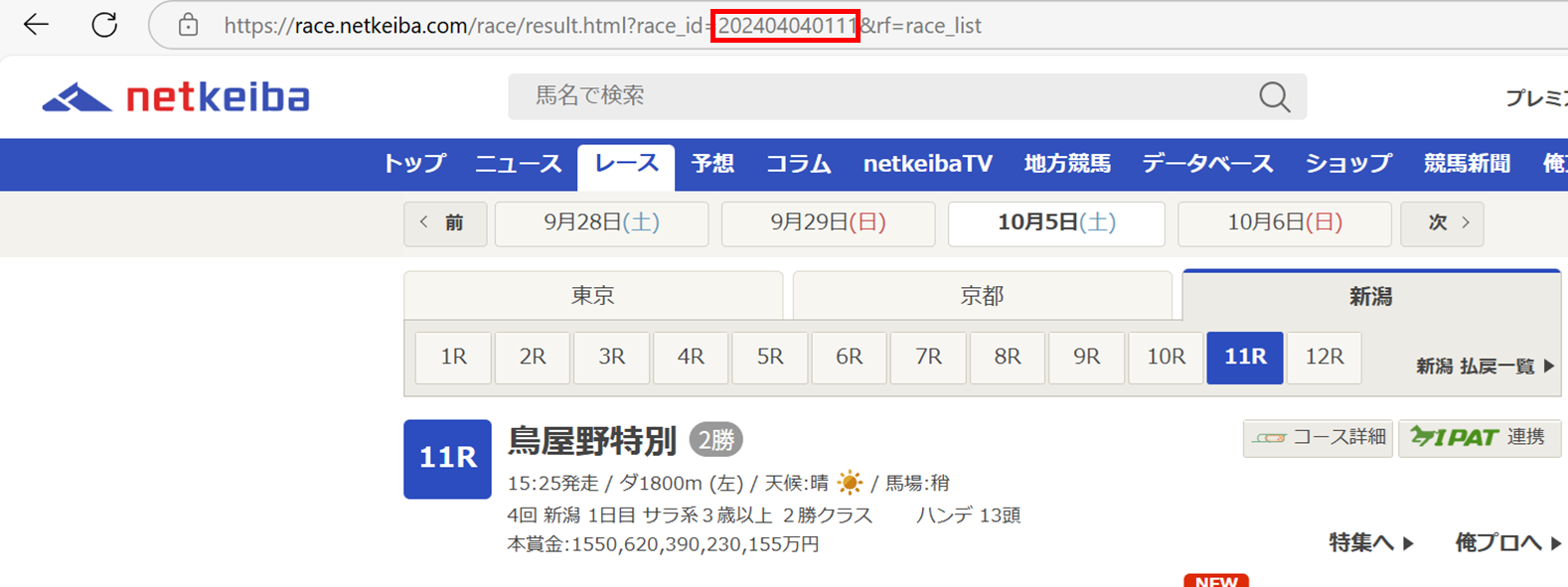

上記の通り、数字が割り当てられます。
競馬場は以下表の数値で割り当てられます。

開催回は1回~6回
日目は1日目~12日目
第〇Rは1R~12R となります。
上記をもとに2023年の全レースのレースIDをリストにて取得します。
race_id_list=[]
for year in range(2023,2024): #開催年 2023年のレース
for place in range(1,11,1): #競馬場 01~10
for kai in range(1,7,1): #開催回 1回〜6回
for day in range(1,13,1): #日目 1〜12日目
for r in range(1,13,1): #第〇R 1~12R
race=str(year)+str(place).zfill(2)+str(kai).zfill(2)+str(day).zfill(2)+str(r).zfill(2)
race_id_list.append(race)for in 関数を用いて、race_id_listに2023年のレースを格納しました。
取得するレースの期間はたとえば2020年から2023年までの区間とする場合は
for year in range(2020,2024)のとすればOKです。
②レース結果の収集~各馬のレース結果の収集~
netkeibaさんの以下のレース結果のページからをスクレイピングします。
表形式になっている各馬のレース結果はpanndasのread_htmlで取得できますが、
レース情報(馬場や距離、フィールドetc)はread_htmlで取得できないため、
BeautifulSoupで取得します。
まずは、各馬のレース結果をread_htmlで取得します。
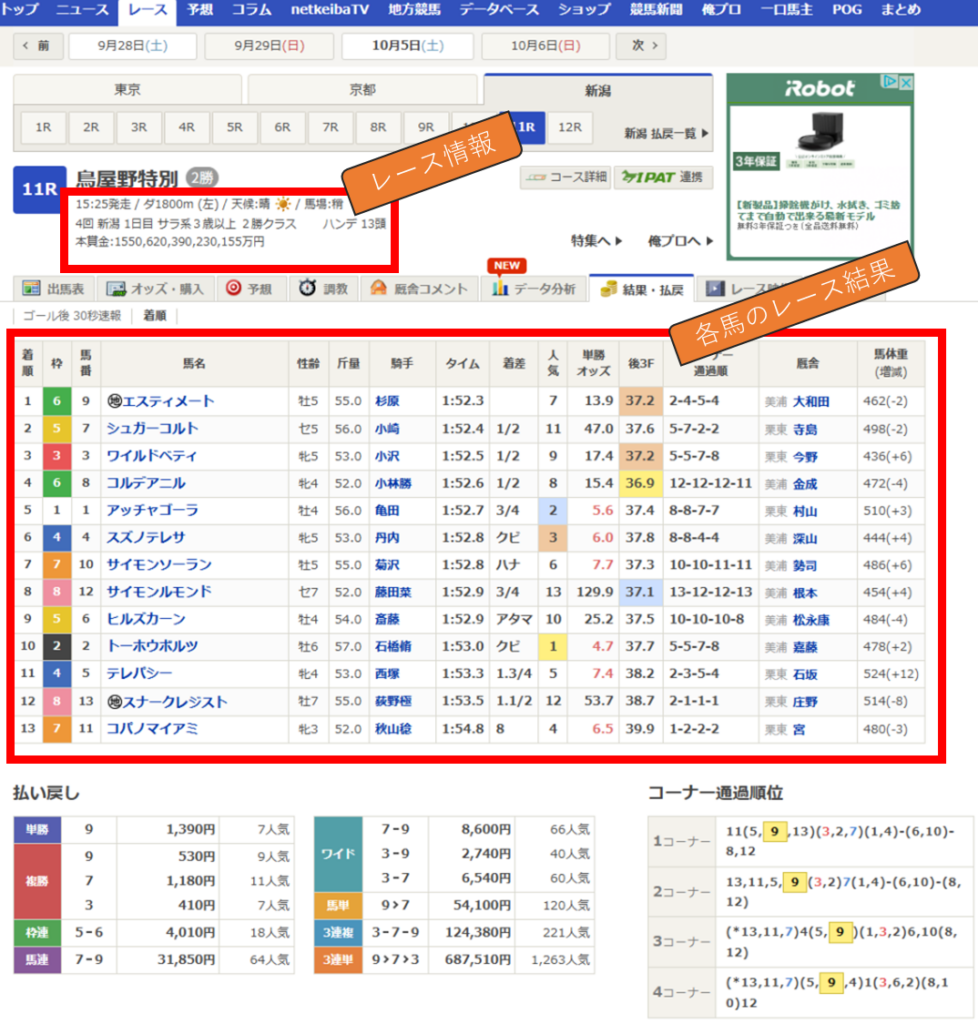
下記の赤枠部分(各馬のレース結果)を取得します。
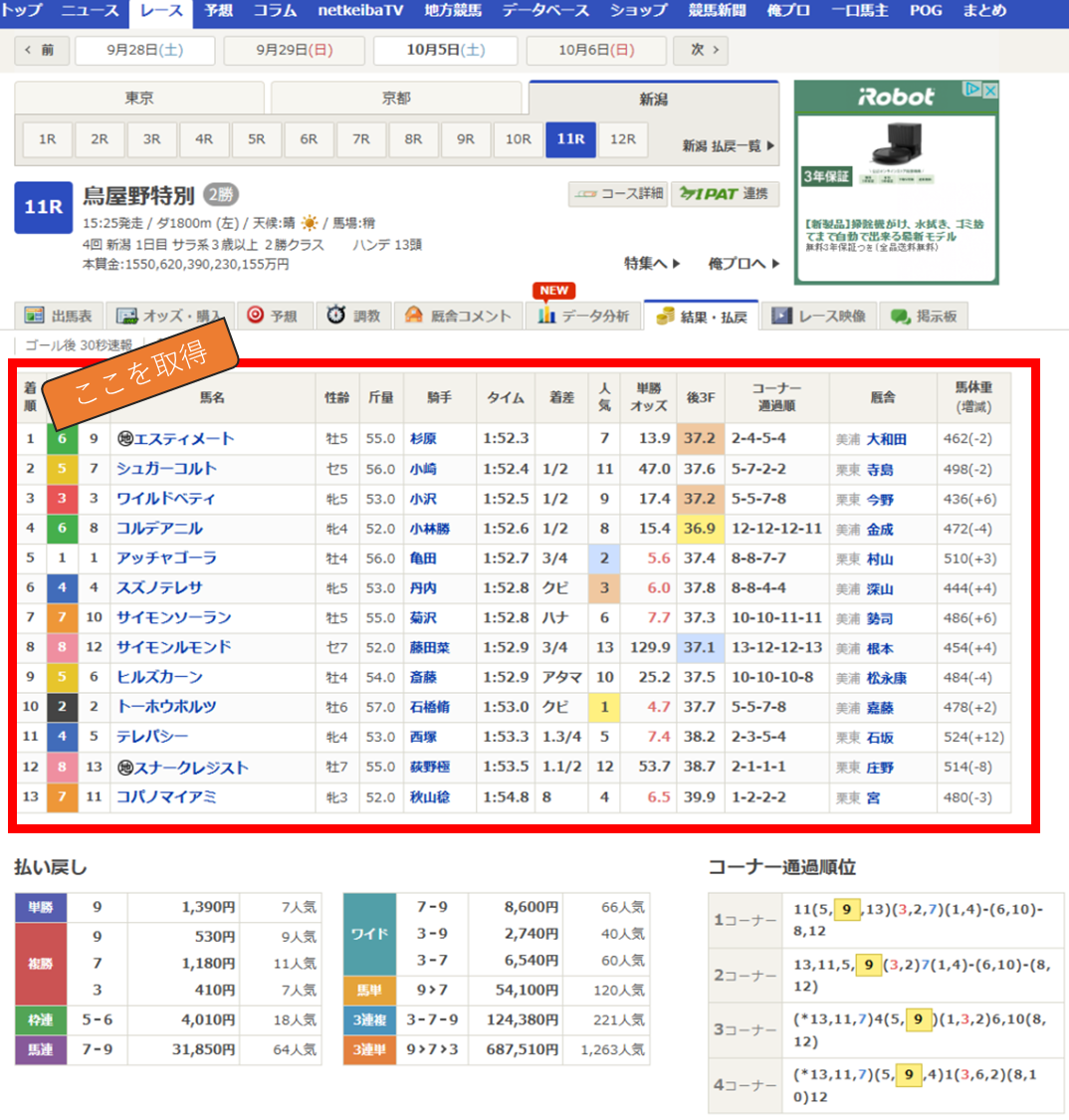
以下のステップで2023年の各馬のレース結果を取得します。
①空のリストを用意する。
各レースの結果を格納するために空のリストを用意します
②2023年のレースIDをrace_id_listからfor in関数を用いてひとつづつ取り出していく
③取り出したレースIDを用いてレース結果ページのURLを作る
④read_htmlで各馬のレース結果を取得する。
⑤取得したレース結果を空のリストに格納する。
⑥リストに格納した各レース結果を一つのデータフレームに統合する。
#レース結果を格納する空のリストを作成する。
race_list=[]
#2023年のレースIDをfor in関数で一つずつ取り出す
#進行状況を確認するため、tqdm関数を使用する
for id in tqdm(race_id_list):
#存在しないレースIDがあるとエラーが発生するため、try関数にてエラーをスキップする。
try:
#レースIDを用いて、レース結果のURLを作成する。
result_url=f"https://race.netkeiba.com/race/result.html?race_id={id}&rf=race_list"
#read_html関数を用いて、レース結果をスクレイピングする。
#レース結果はページの一番最初にある表となるため、[0]をつけて最初の表を指定する
df_result=pd.read_html(result_url,header=0,encoding='euc-jp')[0]
except:
continue
#そのレースIDのレース結果をrace_listに格納する
race_list.append(df_result)
#race_listに格納した各レース結果を一つに統合する。
df_shutuba=pd.concat(race_list,ignore_index=True) #2023年のレース結果をまとめたデータフレームポイント
for in 関数の中で、各レース結果を順々に統合していくこともできるが、処理が非常に遅くなるため、
for in 関数の中では、race_listに各レース結果を格納するのみとしています。
その後、race_listの中の各レース結果をconcat関数にてまとめて統合させます。
③レース結果の収集~レース情報(馬場、距離、フィールドetc)の収集~
次に以下の情報をBeautifulSoupで取得する方法を説明します。
・馬場
・フィールド
・距離
・競馬場
・系種
・クラス
・開催回
・日目
・本賞金
・頭数
説明を簡潔にするために、まずはある1レースについて、上記の情報を取得する方法を説明します。
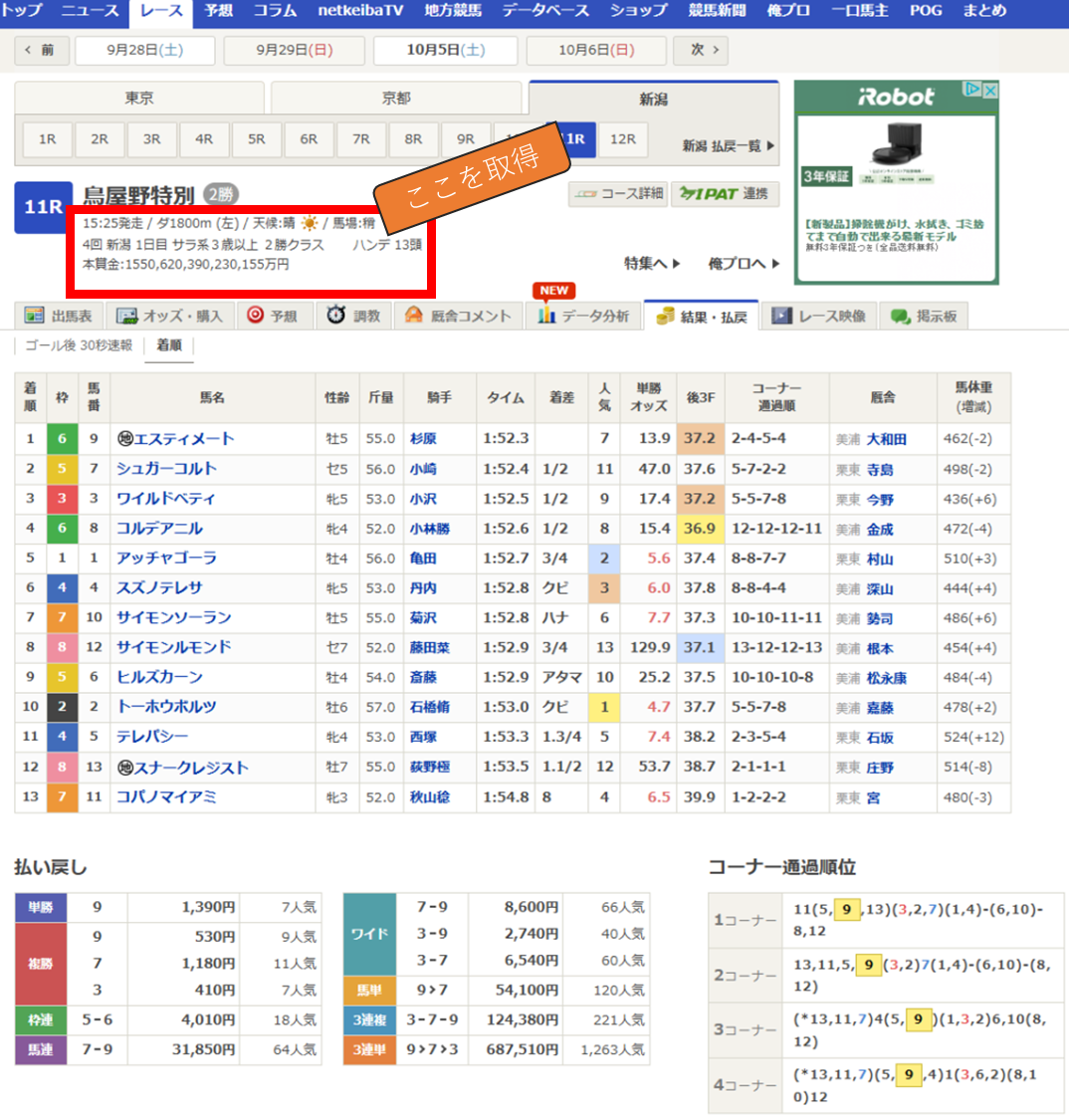
BeautifulSoupでページ情報を取得
BeautifulSoupでページの情報を取得する方法は以下の手順となります。
①取得したいレースのURLを作成する。
②request関数でURL先のページからWEB情報を取得する
res=request.get(URL)で指定されたwebの情報を取得し、その結果を変数resに格納します。
③request関数で取得したWEB情報(変数res)をBeautifulSoupに取り込みます。
BeautifulSoupは以下の記述でデータを取り組みます。
BeautifulSoup(解析対象のHTML, 解析器)
解析対象のHTMLはrequests関数で取得したWEB情報になります。
→WEB情報が格納された変数resに.contentをつけBeautifuSoupに引き渡します。
解析器は高速で処理できる”lxml”を選択します。
(“lxml”はデフォルトではBeautifulSoupに入っていないため、あらかじめ
pip install lxml で”lxml”でインストールしておく必要があります。)
以下のコードでBeautifulSoupにWEB情報を取り組み、その結果を変数soupに格納します。
soup=BeautifulSoup(res.content,”lxml”)
①~③をコードにするといかになります。
from bs4 import BeautifulSoup
import requests
#取得したいレースのURLを作成する
result_url=f"https://race.netkeiba.com/race/result.html?race_id=202404040111&rf=race_list"
#requests関数でURL先のページからWEB情報を取得する。
res=requests.get(result_url)
#BeautifulSoupで取得したWEB情報を解析する
soup=BeautifulSoup(res.content,"lxml")BeautifulSoupにはWEB情報(HTMLデータ)から任意に情報を抽出するためのメソッドがあります。
そのメソッドを利用するために、BeautifulSoupを使うわけです。
馬場、距離、フィールドを取得
WEB上のレース情報を変数soupに格納したので、ここから抽出したいデータを抽出します。
馬場・距離・フィールドをsoupから抽出します。
CSSセレクタというWEN情報(HTML)の住所を示したものを利用して抽出します。
(CSSセレクタについては、他のHPの解説を利用ください)
距離・フィールド・馬場の情報は”div.RaceData01″のCSSセレクタに存在しており、
BeautifulSoupの.select_oneメソッドを用いて情報を抜き出します。
変数soupからCSSセレクタ(”div.RaceData01”)にある情報をselect.oneメソッドで抜き出し、
その結果を変数infoに格納します。
info=soup.select_one(“div.RaceData01”).text
infoには文字列データとして以下が抽出されます。
‘\n15:25発走 / ダ1800m (左)\n/ 天候:晴\n/ 馬場:稍\n’
上記の文字列データからさらに細かい情報を抽出します。
抽出する際は正規表現を利用します。
~距離の取得~
dis=re.findall(r”\d+”,info)[2]
re.findallは正規表現を用いたデータを抽出するメソッドです。
上記のコードは2文字以上数字が連続しているもの(\d+)を探し、3つ目([2])にヒットしたものを
抽出するコードになります。
これにより
‘\n15:25発走 / ダ1800m (左)\n/ 天候:晴\n/ 馬場:稍\n’
という文字列から1800という文字を抽出することができます。
~フィールドの取得~
field=info[info.find(“/”)+2:info.find(“/”)+3]
こちらはフィールドを表す”ダ”というのが,一番最初の”/”の2つ後ろにあるので、
スライスを利用して抽出します。.find(“/”)で”/”が10番目にあることを確認します。
(“/”の前後に空白文字あり)
“ダ”は”/”の2つ後ろにあるため、”ダ”を抜き出すコードとしては、
field=info[info.find(“/”)+2:info.find(“/”)+3]になります。
これにより”ダ”を抽出することができます。
~馬場の取得~
condition=info[info.find(“馬場”)+3:info.find(“馬場”)+4]
こちらもスライスで抽出します。
馬場の状態を表す”稍”は”馬場”という文字において、”馬”の文字から
3つ後ろにあるため、上記のコードとなります。
本賞金、頭数の取得
距離を取得した方法と同様の方法で取得します。
コードは以下になります。
~本賞金の取得~
main_prize=re.findall(r’\d+’, soup.select_one(‘.RaceData02 span:nth-of-type(9)’).text)[0]
~頭数の取得~
head_count=re.findall(r’\d+’, soup.select_one(‘.RaceData02 span:nth-of-type(8)’).text)[0]
開催回、競馬場、系種、日目、クラスの取得
これらは、CSSセレクタで直接値が取得できるため、
以下のコードで取得します。
~開催回の取得~
kai=soup.select_one(‘.RaceData02 span:nth-of-type(1)’).text
~競馬場の取得~
keibajou=soup.select_one(‘.RaceData02 span:nth-of-type(2)’).text
~系種の取得~
breed=soup.select_one(‘.RaceData02 span:nth-of-type(4)’).text
~日目の取得~
nitime=soup.select_one(‘.RaceData02 span:nth-of-type(3)’).text
~クラスの取得~
class_=soup.select_one(‘.RaceData02 span:nth-of-type(5)’).text
〇レース情報(馬場、距離、フィールド 、クラス、競馬場、etc)の取得を
まとめたコードは以下になります。
import pandas as pd
from tqdm import tqdm #進行状況を表示させるライブラリをインストール
import re
from bs4 import BeautifulSoup
import requests
#空のデータフレームを用意する
df_result=pd.DataFrame()
#CSSセレクタ("div.RaceData01")から距離・フィールド・馬場の情報を抽出する。
info=soup.select_one("div.RaceData01").text
#距離を抽出する
dis=re.findall(r"\d+",data1)[2]
#フィールドを抽出する
field=data1[data1.find("/")+2:data1.find("/")+3]
#馬場を抽出する
condition=data1[data1.find("馬場")+3:data1.find("馬場")+4]
#本賞金を取得する
main_prize=re.findall(r'\d+', soup.select_one('.RaceData02 span:nth-of-type(9)').text)[0]
#頭数を取得する
head_count=re.findall(r'\d+', soup.select_one('.RaceData02 span:nth-of-type(8)').text)[0]
#開催回を取得する
kai=soup.select_one('.RaceData02 span:nth-of-type(1)').text
#競馬場を取得する
keibajou=soup.select_one('.RaceData02 span:nth-of-type(2)').text
#系種を取得する
breed=soup.select_one('.RaceData02 span:nth-of-type(4)').text
#日目を取得する
nitime=soup.select_one('.RaceData02 span:nth-of-type(3)').text
#クラスを取得する
class_=soup.select_one('.RaceData02 span:nth-of-type(5)').text
#距離、フィールド、馬場のデータフレームを作成する、
df_result[["距離","フィールド","馬場","本賞金","頭数","開催回","競馬場","系種","日目","クラス"]]=[[dis,field,condition,"main_prize","head_count",kai,keibajou,breed,nitime,class_]]④レース結果の収集~コードの統合~
①レースIDの作成方法
②レース結果の収集~各馬のレース結果~の収集方法
③レース結果の収集~レース情報~の収集方法
の3つを説明しましたが、これらを統合したコードを紹介します。
コードは以下になります。
なお説明は省略しましたが、以下のコードには、
馬IDと騎手ID、日付の値を取得し、データフレームに加えるコードを追加しております。
馬名や騎手名は”各馬のレース結果”から取得できておりますが、netkeibaでは馬と騎手に独自の
IDを付与しており、データ分析をする上では、馬名や騎手名よりも馬IDや騎手IDの方が使いやすいため、コードに加えております。
import pandas as pd
from tqdm import tqdm #進行状況を表示させるライブラリをインストール
import re
from bs4 import BeautifulSoup
import requests
#レースIDを作成
race_id_list=[]
for year in tqdm(range(2023,2024)): #開催年 2023年のレース
for place in tqdm(range(1,11,1)): #競馬場 01~10
for kai in range(1,7,1): #開催1回〜6回
for day in range(1,13,1): #開催日1〜12日目
for r in range(1,13,1): #1~12R
race=str(year)+str(place).zfill(2)+str(kai).zfill(2)+str(day).zfill(2)+str(r).zfill(2)
race_id_list.append(race)
#レース結果を格納する空のリストを作成する。
race_list=[]
#2023年のレースIDをfor in関数で一つずつ取り出す
#進行状況を確認するため、tqdm関数を使用する
for id in tqdm(race_id_list):
#存在しないレースIDがあるとエラーが発生するため、try関数にてエラーをスキップする。
try:
#レースIDを用いて、レース結果のURLを作成する。
result_url=f"https://race.netkeiba.com/race/result.html?race_id={id}&rf=race_list"
#read_html関数を用いて、レース結果をスクレイピングする。
#レース結果はページの一番最初にある表となるため、[0]をつけて最初の表を指定する
df_result=pd.read_html(result_url,header=0,encoding='euc-jp')[0]
except:
continue
try:
#レース情報をスクレイピングする。
#requests関数でURL先のページからWEB情報を取得する。
res=requests.get(result_url)
#BeautifulSoupで取得したWEB情報を解析する
soup=BeautifulSoup(res.content,"lxml")
#CSSセレクタ("div.RaceData01")から距離・フィールド・馬場の情報を抽出する。
info=soup.select_one("div.RaceData01").text
#距離を抽出する
dis=re.findall(r"\d+",info)[2]
#フィールドを抽出する
field=info[info.find("/")+2:info.find("/")+3]
#馬場を抽出する
condition=info[info.find("馬場")+3:info.find("馬場")+4]
#本賞金を取得する
main_prize=re.findall(r'\d+', soup.select_one('.RaceData02 span:nth-of-type(9)').text)[0]
#頭数を取得する
head_count=re.findall(r'\d+', soup.select_one('.RaceData02 span:nth-of-type(8)').text)[0]
#系種を取得する
breed=soup.select_one('.RaceData02 span:nth-of-type(4)').text
#開催回を取得する
kai=soup.select_one('.RaceData02 span:nth-of-type(1)').text
#競馬場を取得する
keibajou=soup.select_one('.RaceData02 span:nth-of-type(2)').text
#日目を取得する
nitime=soup.select_one('.RaceData02 span:nth-of-type(3)').text
#クラスを取得する
class_=soup.select_one('.RaceData02 span:nth-of-type(5)').text
#日付取得
day= soup.find('meta', {'name': 'description'})
day=day['content'].split(' ')[0]
df_result["日付"]=day
#レース結果のデータフレーム(df_result)にレース情報のデータを加える
df_result["距離"]=dis
df_result["フィールド"]=field
df_result["馬場"]=condition
df_result["本賞金"]=main_prize
df_result["頭数"]=head_count
df_result["系種"]=breed
df_result["開催回"]=kai
df_result["競馬場"]=keibajou
df_result["日目"]=nitime
df_result["クラス"]=class_
df_result["日付"]=day
#レースIDをdf_resultに追加する。
df_result["レースID"]=id
except:
pass
try:
#馬のIDを取得
horse=soup.select("tbody > tr > td:nth-child(4)> span")
horse_id=[]
for uma in horse:
try:
uma=str(uma)
uma_id=re.findall(r"\d{3}[A-Za-z0-9]{7}",uma)[0]
horse_id.append(uma_id)
except:
continue
df_result["馬ID"]=horse_id
#騎手のIDを取得
kisyu=soup.select("td.Jockey")
kisyu_id=[]
for k in kisyu:
try:
k=str(k)
k_id=re.findall(r'recent/(\w{5})',k)[0] #recent/の後の英数字を5文字取り出す。
kisyu_id.append(k_id)
kisyu_id=kisyu_id[:df_result.shape[0]]
except:
continue
df_result["騎手ID"]=kisyu_id
df_result["騎手ID"] = df_result["騎手ID"].apply(lambda x: "J" + str(x))
except:
pass
#そのレースIDのレース結果をrace_listに格納する
race_list.append(df_result)
#race_listに格納した各レース結果を一つに統合する。
keiba_data=pd.concat(race_list,ignore_index=True) #2023年のレース結果をまとめたデータフレーム
keiba_data=keiba_data.rename(columns={'馬 番':"馬番","着 順":"着順","人 気":"人気",'馬体重 (増減)':'馬体重(増減)','騎手 斤量':'騎手斤量'})
keiba_data.to_csv("競馬データ.csv",index=False)最後にdf_shutuba.to_csv(“競馬データ.csv”,index=False)で収集したデータをcsvにして保存しております。
収集データは以下の形となっております。

投稿者プロフィール

-
独学でpythonを学び競馬予測しています。これまでの競馬成績は以下の通り。回収率150%を目指します。
2021年回収率:119%
2022年回収率:104%
2023年回収率:121%
2024年回収率:88%
最新の投稿
- 競馬データの前処理・特徴量作成2024年12月30日騎手勝率
- 競馬よもやも話2024年11月28日競馬予想モデルと狙うべき馬券
- 競馬データの前処理・特徴量作成2024年11月27日馬年齢(日齢)と日齢を使った派生特徴量
- 競馬よもやも話2024年11月24日予想モデルの改良タイミング
