
馬場指数とは
その日の馬場状態を数値化したものです。
時計の掛かる馬場状態をプラスの値、時計の出やすい状態をマイナスの値で表示しています。
水準前後の馬場状態になればなるほどゼロに近づきます。
馬場指数の用途
馬場指数は競走馬の速さの指数であるスピード指数の算出に使用します
スピード指数の算出式は以下です。

馬場指数の算出
馬場指数は競馬場ごとに芝とダートで算出します。
算出は以下のステップで行います。
①競馬場の個々のレース(12R)について、下記の式で馬場指数を算出する。
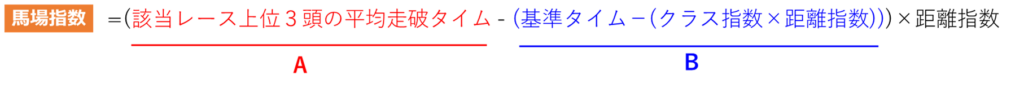
Aは実際のそのレースでの平均走破タイムとなります。
Bですが、基準タイムにはクラスの補正がかかっていないため、該当レースのクラスに応じてクラスの補正をかけます。これにより、そのクラスがその競馬場で出す基準のタイムが算出できます。
A-Bはそのレースの基準のタイム(B)に対して、レース結果(A)が上回ったのか、下回ったのかを表します。A-Bが+になれば、基準タイムよりレース結果が遅かったとなり、馬場状態は不良であったとなります。-になれば基準タイムより早かったとなり、馬場状態は良好であったとなります。
②その日のその競馬場の馬場指数の結果を芝とダートに分け平均を取り最終馬場指数を算出する
①で求めた馬場指数はその競馬場のある一つのレース結果をもとに算出したものです。誤差やノイズを含むため、最終的な馬場指数はその競馬場の全レースの馬場指数を芝とダートに分け平均をとったものになります。

pythonの実装コード
Pythonでコードを書くと以下のようになります。
import pandas as pd
keiba_data=pd.read_csv(〇〇)#〇〇には競馬データ.csvのファイルパスを入力
#馬場指数算出用に必要なデータのみ取り出す
keiba_data=keiba_data[["レースID","タイム","着順","競馬場","距離","フィールド","クラス"]].copy()
#ラウンドだけ除いたレースIDを作る
#1~3着のみのデータにする。
keiba_data= keiba_data[keiba_data['着順'] <= 3]
#groupby(["レースID","競馬場","距離","フィールド","クラス"])で平均(mean)をとることで、各レースの平均走破タイムを算出
#マルチインデックスになっているので.reset_indexで通常のデータフレームに戻す
keiba_data=keiba_data.groupby(["レースID","競馬場","距離","フィールド","クラス"]).mean().reset_index()
#タイムのカラムの値は1~3着馬の平均走破タイムになっているので、カラム名を変更する。
keiba_data=keiba_data.rename(columns={'タイム':"平均走破タイム"})
#基準タイムを読み取り
standard_time=pd.read_csv(〇〇)#〇〇には基準タイム.csvのファイルパスを入力
#基準タイムをkeiba_dataに結合
keiba_data = pd.merge(keiba_data, standard_time[['競馬場', '距離', 'フィールド', '基準タイム']], on=['競馬場', '距離', 'フィールド'], how='left')
#距離指数を読み取り
standard_dis=pd.read_csv(〇〇)#〇〇には距離指数.csvのファイルパスを入力
#距離指数をkeiba_dataに結合
keiba_data = pd.merge(keiba_data, standard_dis[['距離', 'フィールド',"距離指数"]], on=[ '距離', 'フィールド'], how='left')
#クラス指数を読み取り
standaed_class=pd.read_csv(〇〇)#〇〇にはクラス指数.csvのファイルパスを入力
#クラス指数をkeiba_dataに結合
keiba_data= pd.merge(keiba_data, standaed_class[["競馬場",'距離', 'フィールド',"クラス","クラス指数"]], on=["競馬場", '距離', 'フィールド',"クラス"], how='left')
#同日の競馬場のレースを識別するために、レースIDからラウンド数を除いたレースID_R抜きを作成する。
keiba_data["レースID_R抜き"]=keiba_data["レースID"].astype(str).str[0:10]
keiba_data["レースID_R抜き"]=keiba_data["レースID_R抜き"].astype("int64")
#芝フィールドでの馬場指数算出
#keiba_dataから"芝"のレースだけ抜き出す
baba_data_shiba=keiba_data[keiba_data['フィールド'].str.contains("芝")].copy()
#個々のレースの馬場指数を算出する、
baba_data_shiba["個々レースの馬場指数"]=(baba_data_shiba["平均走破タイム"]-(baba_data_shiba["基準タイム"]-(baba_data_shiba["クラス指数"]*baba_data_shiba["距離指数"])))* baba_data_shiba["距離指数"]
#その競馬場のその日の全芝レースの馬場指数の平均を取り、最終的な馬場指数(芝)を算出する。
baba_data_shiba["馬場指数"]=baba_data_shiba.groupby("レースID_R抜き")["個々レースの馬場指数"].transform("mean")
#ダートフィールドでの馬場指数算出
#keiba_dataから"ダート"のレースだけ抜き出す
baba_data_dato=keiba_data[keiba_data['フィールド'].str.contains("ダ")].copy()
#個々のレースの馬場指数を算出する、
baba_data_dato["個々レースの馬場指数"]=(baba_data_dato["平均走破タイム"]-(baba_data_dato["基準タイム"]-(baba_data_dato["クラス指数"]*baba_data_dato["距離指数"])))* baba_data_dato["距離指数"]
#その競馬場のその日の全ダートレースの馬場指数の平均を取り、最終的な馬場指数(ダート)を算出する。
baba_data_dato["馬場指数"]=baba_data_dato.groupby("レースID_R抜き")["個々レースの馬場指数"].transform("mean")
#芝データとダートデータの馬場指数を統合する。
standard_baba=pd.concat([baba_data_shiba,baba_data_dato],axis=0)
#必要なデータのみに絞る
standard_baba=standard_baba[["レースID","フィールド","馬場指数"]]
standard_baba.to_csv("馬場指数.csv",index=False)
